Efficient Kafka Streaming with Batching and Compression
- Melvin Jones
- May 15, 2025
- 2 min read

Updated: May 27, 2025
You can download the source code for this project and run it in your own local environment by clicking here. |
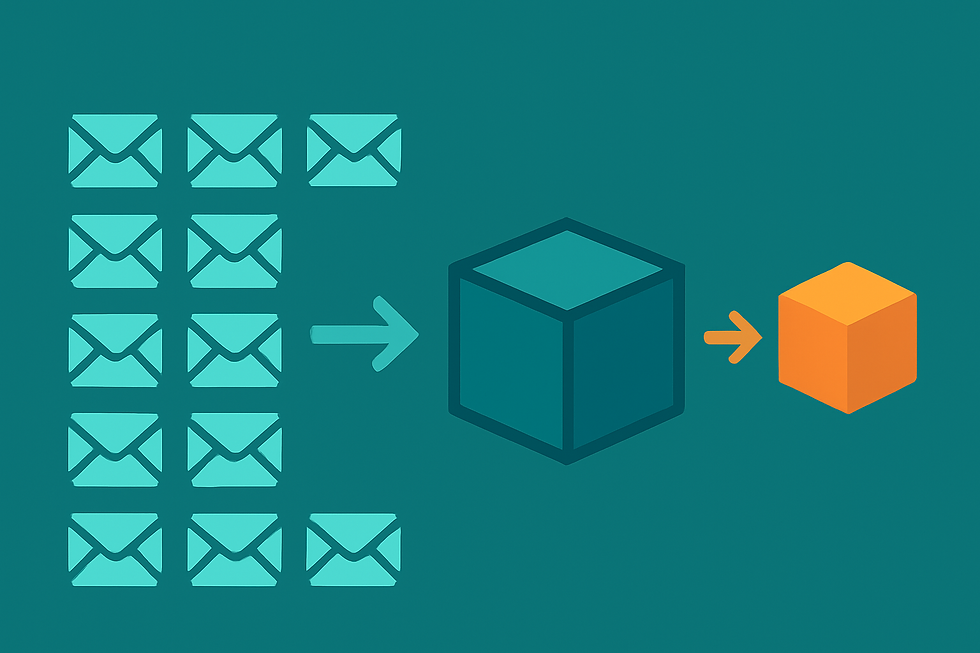
In my work building high-throughput data pipelines, I discovered that sending thousands of tiny JSON messages one by one causes serious overhead: each message incurs network handshakes, protocol framing, and disk I/O. To solve this, I wrote a demo that shows how to batch and compress messages before sending them to Kafka, and it made a dramatic difference in throughput and resource use.
With batching, the producer collects dozens or hundreds of JSON records in memory and then emits them all at once in a single Kafka message. Under the hood, the code waits until it has reached a batch size limit or a short time-based linger, then concatenates the JSON strings with delimiters into one byte buffer. This reduces the number of produce() calls and shrinks the total amount of protocol and broker metadata.
On top of batching, I apply zlib compression (or you can configure LZ4 on the Kafka client). The compressor scans the large payload, finds repeated field names and structural patterns, and packs the data into a much smaller binary. As a result, I routinely see payload sizes drop by 70–90%. That shrinks network traffic, lowers cloud egress fees, and speeds up replication across Kafka brokers.
On the consumer side, the process simply reverses: one poll() call retrieves the compressed batch, we decompress it back into the original byte stream, split on the record delimiter, and parse each JSON object. From the consumer’s perspective, nothing changes except it now processes hundreds of logical records per Kafka message.
Real-world benefits of this approach include:
• Dramatically higher throughput. Fewer produce() calls and larger I/O blocks let you push tens or hundreds of thousands of events per second through a single broker.
• Lower resource consumption. Reduced network packets, fewer disk seeks, and less CPU overhead in the broker.
• Configurable latency vs. efficiency trade-off. You can tune batch size and linger time to balance end-to-end latency against bandwidth and throughput.
• Cost savings. Compressed payloads mean reduced cloud data transfer and storage costs.
If you’d like to see the full working example, complete with Docker Compose, Python producer and consumer code, check out the repo at https://github.com/mjones3/kafka-batch-compress-demo.
Comments